
PDF remediation is a time-consuming but necessary part of digital accessibility for any organization. It’s tempting to just click Adobe’s free “auto-tagging” feature to shortcut the task of making PDFs accessible for people with disabilities. But auto-tagging often won’t produce an instantly accessible PDF on its own. You’ll need to manually verify the document is tagged correctly, no matter what kind of automation you employ.
Adobe isn’t an accessibility tool
Adobe Acrobat wasn’t designed as an accessibility tool. It is a publishing tool, like Microsoft Word or Google Docs (both of which actually have better native accessibility tools built-in). Using the auto-tag feature isn’t the one-click accessibility solution some may think it is. Auto-tagging a document can be a useful starting point for remediation, but it is not meant to be a one-and-done solution. After using the auto-tag function, the remediator needs to manually verify the accuracy of the tags and resolve the errors that remain. This involves interaction with the complex and intricate tag tree structure in Adobe.
The Adobe auto-tagging features aren’t “smart.” They are based on static definitions derived from styling in popular publishing tools. So they cannot interpret variations in styling among the many documents that may pass through the program.
Let’s take a look at some of the shortcomings of auto-tagging PDFs in Adobe.
Auto-tagging a Sample Document
Here is a sample document that contains a few common elements. It contains headings, images, text that is really an image, a list, and a table.

Auto-tagging this document using Adobe produces a number of errors. Additionally, another method of validation is required to ensure accessibility because not all errors will be caught by the Adobe Checker. Auto-tagging errors make the document inaccessible, meaning someone attempting to read it using assistive technology (such as a screen reader or connected Braille display) will not be able to access the information it contains.
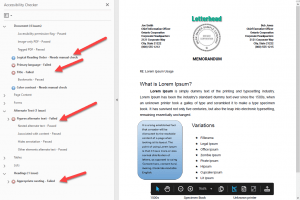
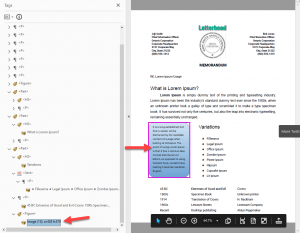
Adobe tag tree after auto-tagging
We can examine the Adobe tag tree after auto-tagging this PDF and see the results.
Text
The first issue lies with the text at the top of the page. The word “Letterhead,” isn’t identified by Adobe as text. It is tagged as part of an image.
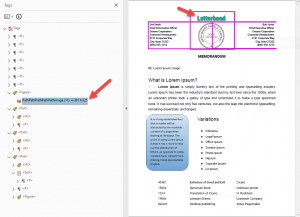
Headings
The next issue is that the word Memorandum is tagged as Heading level 3, but should be tagged as a Heading level 1. It clearly matches some style definition that tells the auto-tagger that this size and weight of font is level 3.
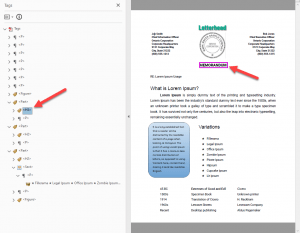
Additionally, Adobe has auto-tagged the subsequent headings as Headings level 2, which is an error in logical heading structure, if the H3 has come first.
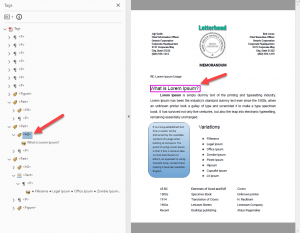
Text not OCR’d
Next is the text on the left, below the first paragraph inside the box. Because it is identified as an image, and the text isn’t OCR’d, anyone using assistive technology will be unable to read the information contained in the box. Adobe auto-tagging does not include its OCR capabilities, so there is no way for auto-tagging to resolve this issue. It is also of note that the image is tagged at the end of the reading order, which is not where it belongs. It should be slotted before the “Variations” heading to its right.
List
Now let’s take a look at the list. Despite having bullets, these bullets are not “commonly used” bullets, and Adobe has auto-tagged this list as text using a P-tag. Again, the Adobe auto-tag definition of a list doesn’t allow for “unusual” bullets. An assistive technology user will just be given a string of words with no indication of their relationship, and will not know it is a list.
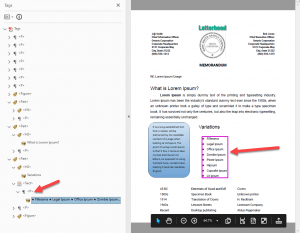
Table
The Adobe auto-tagging also failed to identify the tabular information at the bottom of the page as a table.
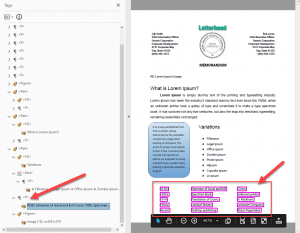
This text is contained in a P-tag (inside the indicated container in the tag tree). The content will be presented to an assistive technology user as an unrelated string of words instead of a table of related information. This particular table apparently doesn’t fit the Adobe definition of a table containing cells.
Auto-tagging results in errors and is a liability
Even this simple one-page document was not correctly auto-tagged by Adobe. There are an unacceptable number of tagging errors and it is not fully usable by someone accessing it using assistive technology. Presenting this document on your website or via email using Adobe auto-tagging would constitute a violation of the ADA and Section 508. It could result in a complaint or even a lawsuit. More importantly, the end-user would be unable to obtain the information you intend to convey. Accessibility is about providing the same information to EVERYONE.
Fixing auto-tagging errors in Adobe requires many steps
In order to make this document fully accessible, the remediator would have to go back into the Adobe tag tree, item by item, and correct all the errors created by the auto-tagging. The Adobe remediation process is very manual, tedious, and time-consuming. The software is a publishing tool, not a dedicated accessibility solution.
The process of fixing just the list could take as much as half an hour. Here is how it works:
- Using the touch-up reading tool, select each bullet and separate it from each list item, because they are contained inside a single tag
- Change the new tags containing the bullets into “Lbl” tags
- Change the tags containing the text into “LBody” tags
- Then open the tag tree and manually creating “LI” tags
- Nest the “Lbl” and “LBody” tags inside the “LI” tags, one by one
- Then put all the “LI” tags into a “List” tag by hand
A similarly complex process is required to fix the table in this document.
Much time remediating in Adobe is spent simply FINDING the offending tag within the lengthy and complex tag tree in order to make corrections. This document is only one page and the tag tree contains many items, not all of which are in the correct order.
Can automation result in accessible PDFs?
So does this mean automation is never the solution? No, it doesn’t. For Adobe, auto-tagging at least provides a starting point. But there is software available that uses automation in a way that simplifies the process AND provides accuracy. This type of automation is accurate if the content fits the existing definitions, but how those definitions are derived makes a large difference in the results, as you will see.
Equidox PDF remediation software uses machine learning-powered smart detection tools to simplify the process of making PDFs accessible. However, the automation employed by Equidox results in accessible documents because you can manually adjust where the tags belong and how the table or list items are detected as you go. Part of the process requires manual decisions, but it is up to 90% faster than correcting errors in Adobe. Not only that, because of the HTML Preview function that Equidox provides, you can check your work as you go.
Let’s take a look at how Equidox would make this document accessible.
Equidox machine learning-powered automation
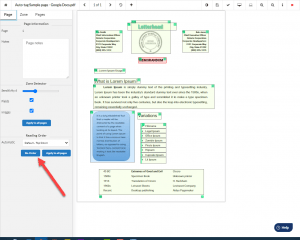
First, using the Zone Detector, Equidox divides the page elements into zones. These zones determine how the tags are applied when the document is output from Equidox as a PDF document.
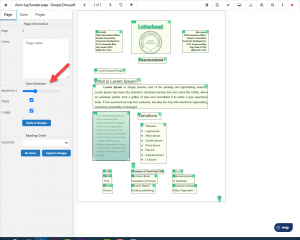
Next, Equidox easily sets the headings using keyboard shortcuts. Simply select the desired zone and hit the correct heading number on the keyboard. “1” for heading level 1, “2” for heading level 2, etc.
Set the Alt text for images by selecting the zone and adding the alt text description.
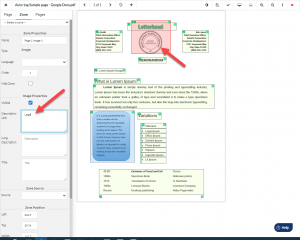
Set the list using the smart List Detector. Two clicks and the list is tagged. That’s it. Two clicks and done. No searching the tag tree, no building of list items. Adjust the detector to correctly identify the list, and check whether the list is correctly tagged in the HTML preview.
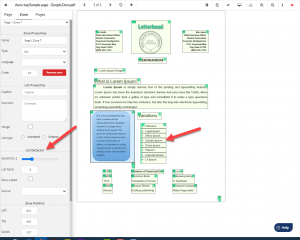
Same for the table – select the text that comprises the table, set the zone to “Table” by hitting “T” on your keyboard, choose Table Editor, and use the smart column and row Detectors to set your table tags. A few clicks and the table is tagged. Equidox can even automatically write the structural data (how many column and row headings and spanned cells) into the table summary for you.
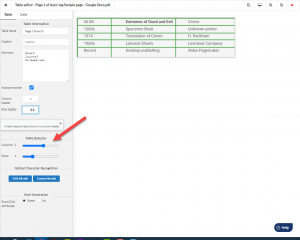
As for the image that is actually text, with Equidox you can artifact the image and create a zone around the picture of text. Then choose “OCR” and Equidox will convert the image to text.
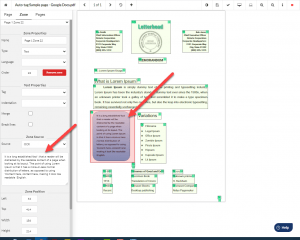
Lastly, you can quickly set the reading order using Equidox’s “Re-order” button. Make adjustments using Equidox’s reading order decimal system to insert tags in the reading order. There is no need to find and manipulate items within a complicated tag tree as there is in Adobe.
Automation is possible with the right tool
Remediating this table in Equidox would take a few minutes for an experienced user. The automation utilized by Equidox produces accessible and accurate results because it can be very quickly and easily adjusted and checked in the HTML preview. The same task using the Adobe auto-tagging feature would involve many steps to correct the resulting errors.
Automation isn’t out of the question for PDF accessibility. However, in any application, incorporate accessibility into the remediation process rather than replacing it. Whenever you are provided an “automated” accessibility feature, you need to ensure that what it is providing is, in fact, accessible. You should always validate your work using a screen reader, not just an accessibility checker.
Choose your automation tools wisely, and select one that saves you the most time and results in the most accessible results.
Want to learn more about Equidox PDF accessibility automation? Contact us for a free demonstration!
Ryan Pugh
Ryan Pugh | Director of Accessibility | Equidox Prior to joining Equidox, Ryan Pugh served as an Access Technology Analyst for the National Federation of the Blind (NFB) in Baltimore, where he was the NFB's focal point for accessibility and usability testing. He conducted intensive web accessibility audits for compliance with Web Content Accessibility Guidelines (WCAG) 2.0 AA for numerous Fortune 500 companies, including some of the world’s largest online retailers, notable colleges and universities, government agencies at the federal, state, and local levels and for other non-profit institutions. He also delivered accessibility training workshops and managed the NFB’s document remediation program, specializing in PDF accessibility.