
All organizations have them. Old, scanned documents that need to be kept for what feels like forever. And some of those have to be posted on the internet. Worse, there are old scanned documents that were faxed. Maybe a few times… And right, yes, they are crooked on the page.
Assistive technology can’t read a scanned PDF
Scanned text is not actually digital text, it is a picture of text. A picture cannot be “read” by assistive technology such as screen readers or Braille displays. They can only read text that is digitally tagged as “text.” That means a scanned document is completely inaccessible.
Making scanned documents accessible
So how do you make those accessible? The scanned pages require Optical Character Recognition (OCR) technology to convert them into readable digital text. This means OCR encodes the text and then a digital tag is applied to the now encoded text that allows assistive technology to read it. This OCR’d digital text is also recognizable by other digital text authoring programs like MSWord, Google Docs, or the like. You cannot copy and paste text from a scanned document into a Google Doc, but you can with OCR’d text.
The OCR’d text must then be tagged in the correct reading order. Additionally, any headings, lists, tables, links, and image descriptions in the scanned document must also be tagged.
OCR isn’t perfect
The more readable and less pixelated the scanned image, the better results you will get. OCR technology has come a long way in the last decade. However, no OCR engine is infallible, and in many cases, some corrections will be required in order to convey the correct information to assistive technology.
Things that affect accuracy are the “speckling” effect from repeated faxing, pixelation of the imaged text from poor scanning technology, italics, and unusual fonts. In this example, you can see how the scanned text has been OCR’d and some errors have occurred due to the quality of the scanned document and the italics used in the source document.

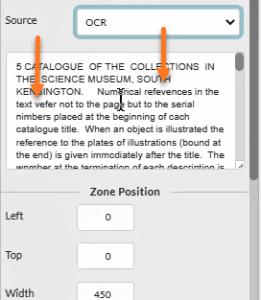
Equidox speeds up the process
Using Equidox software, tagging a scanned page is much easier than with other tools. You can OCR any section of text on any page loaded into Equidox, or you can choose OCR All Pages. If no text is detected on import, Equidox will automatically OCR the imported page with the message “No content on Page 1, sending to OCR.”
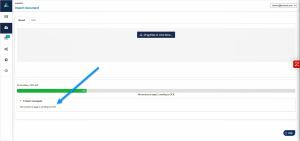
Equidox Import Tab
If the page isn’t automatically OCR’d, simply select the zone in Equidox and choose OCR from the Zone Source on the Zone Tab, and click the “Convert to text” text button.
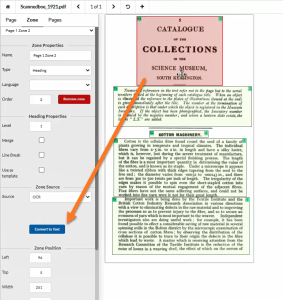
Equidox Convert to Text button
Once the text has been OCR’d, check the accuracy and make any necessary corrections in the Zone Source box.
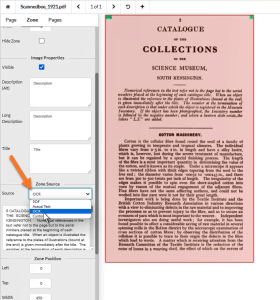
Equidox OCR Box
Adding navigation and structure to scanned text
It is notable that content edited in the Zone Source box cannot contain any paragraphs or headings. The text within the Zone Source box functions as “alt text” for the image of text that has been scanned. This means that if an entire page is OCR’d, it might be a lot of uninterrupted content without any headings or paragraph breaks for an assistive technology user. Because of this, it may sometimes be best to create separate OCR zones within a page to allow necessary navigation tags. Zone source can be used for any field within Equidox that contains text – headings, paragraphs, quote blocks, links, etc.
In this example, we can see that the image zone for the page has been removed and text zones have been drawn over the scanned text, and some zones have been set as headings (blue arrows). Each of these zones will then be OCR’d to create digital text that assistive technology can read. (Orange arrow).
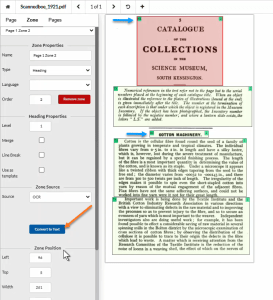
Equidox OCR Button
The resulting text would look like this in your Equidox Preview:

Equidox Preview Page
Now the scanned document has been OCR’d, checked for accuracy, and had navigation and structural tags added, it is not only readable for someone using assistive technology, but it is navigable and searchable.
Scanned Documents Aren’t Always Exempt from Accessibility Mandates
While many digital accessibility mandates cite archived content as exceptions, including old documents that have been scanned, these aren’t necessarily exempt. If the documents are referred to in current content or are used by the public, they must be accessible. It will be necessary to OCR and then tag any scanned PDF documents that fall into this category. The rule of thumb is that if the document is being used in any way, it should be accessible for everyone.
Scanned documents can be accessible
You can make nearly any scanned document accessible using Equidox. Even crooked, badly pixelated documents can have text zones created and edited to produce an accessible version of the scanned original document. Headings, links, and other text fields can be added to aid in navigation and accuracy. While some documents may require more effort than others, any PDF document can be made accessible.
Tammy Albee
Tammy Albee | Director of Marketing | Equidox Tammy joined Equidox after four years of experience working at the National Federation of the Blind. She firmly maintains that accessibility is about reaching everyone, regardless of ability, and boosting your market share in the process. "Nobody should be barred from accessing information. It's what drives our modern society."

We can help
Looking for an easier way to make your archived scanned documents accessible and compliant? Contact us for a free demonstration.